并行计算-Hardware
Acknowledgement
The content of this post is based on a summary of the Parallel systems (COMP8300) course at the Australian National University, which I have greatly benefited from. Thanks to lecturers Dr. Alberto F. Martin, Prof. John Taylor.
Hardware
Single processor design
Instruction pipelining (Single instruction issue)
Break instructions into \(k\) stages each that are overlapped in time.
e.g. (\(k = 5\) stages)
FI = fetch instruction
DI = decode instruction
FO = fetch operand
EX = execute instruction
WB = write back
Ideally, one gets \(k\)-way asymptotic parallelism speedup.
However, hard to maximize utilization in practice: - Constrained by dependencies among instructions; CPU must ensure result is the same as if no pipelining. - FO & WB stages may involve memory accesses and my possibly stall hte pipeline. - conditional branch instructions are problematic: the wrong guess may require flushing succeeding instructions from the pipeline and rolling back
Super-scalar execution (Multiple instruction issue)
Simple idea: Increase execution rate by using \(w\ge2\) (i.e., multiple) pipelines
\(w\) (mutually independent) instructions are (tried to be) piped in parallel at each cycle
Ideally it offers \(kw\)-way parallelism
However, a number of extra challenges arise: - Increase complexity: HW has to be able to resolve dependencies at runtime before issuing simultaneously several instructions - Some of the functional units might be shared by the pipelines (aka resource dependencies) - As a result, ? TODO
Some remedies: pipeline feedback, branch prediction + speculative execution(推测执行), out-of-order execution (乱序执行 OOO) , compilers
Limitations of instruction-level parallelism (ILP)
CPU does a lot of wasted work that can just not be written back due to branch mis-predictions.
Limitations of memory system performance
Memory latency and bandwidth are critical performance issues - caches: reduce latency and provide improved cache to CPU bandwidth - multiple memory banks: improve bandwidth (by parallel access)
Cache memory is effective because algorithms often use data that: - was recently accessed from memory (temporal locality) - was close to other recently accessed data (spatial locality)
Going explicitly parallel
- Performance of single processor is irremediably limited by clock rate
- Clock rate in turn limited by power consumption, transistor switching time, etc.
- ILP allows multiple instructions at once, but it is limited by dependencies
- Many problems are inherently distributed/exhibit potential parallelism
Parallel hardware
Overview
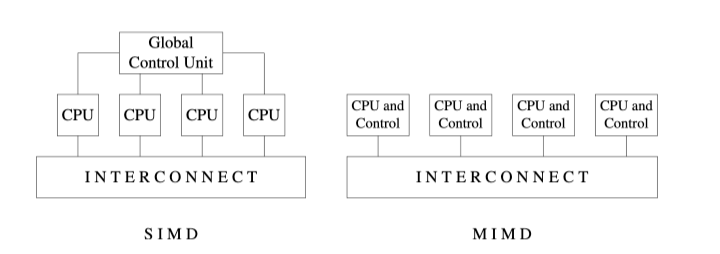
- Flynn's taxonomy of parallel processors (1966, 1972)
- (SISD/SIMD/)SIMD/MIMD
- Message-passing versus shared-address space programming
- UMA (Uniform memory access) versus NUMA shared-memory computers
- Dynamic/static networks
- Evaluating cost and performance of static networks
SIMD and MIMD in Flynn's taxonomy
SIMD
also known as data parallel or vector processors (very popular in the 70s and 80s)
examples: GPUs; SPEs on Sony's PS3 IBM CellBE
perform their best with structured (regular) computations (e.g. image processing)
MIMD
examples: quad-core PC; 2x24-core Xeon CPUS
Most successful model for parallel architectures - more general purpose than SIMD, can be built out of off-the-shelf components - extra burden to programmer
Some challenges for MIMD machines - scheduling: efficient allocation of processors to tasks in a dynamic fashion - synchronization: prevent processors accessing the same data simultaneously - interconnect design: processor to memory and processor to processor interconnects. Also, I/O network - often processors dedicated to I/O devices - overhead: inevitably there is some overhead associated with coordinating activities between processors, e.g. resolve contention for resources - partitioning: partitioning a computation/algorithm into concurrent tasks might not be trivial and require algorithm redesign and/or significant programmign efforts
Logical classification of parallel computers
- Message-passing (distributed address space) parallel computers
- Shared address space parallel computers
Physical classification
- Shared-memory multiple processors
- Distributed-memory multiple processors
Shared address space
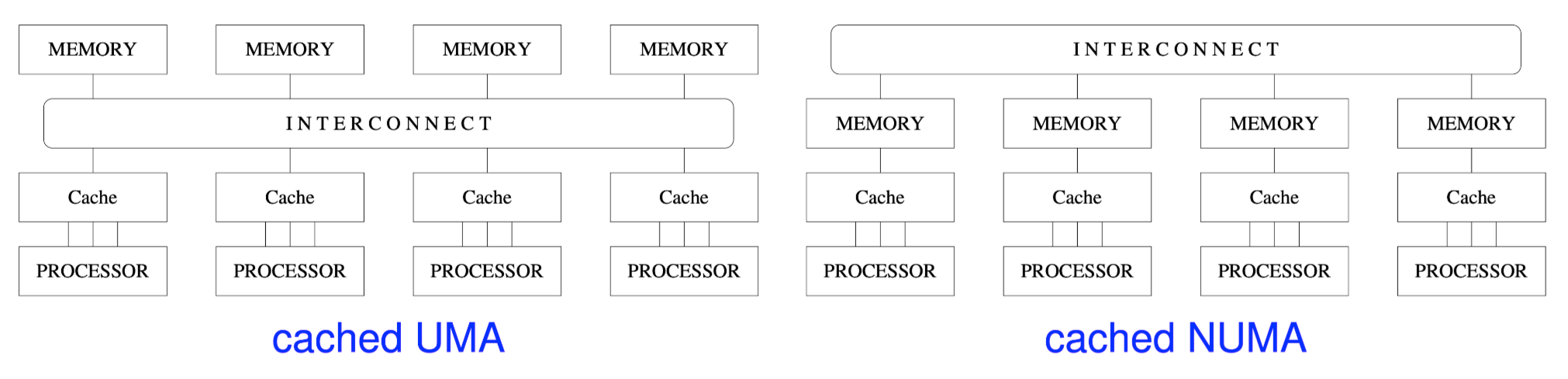
UMA and NUMA
example: QuadCore laptop
UMA