寄存器清零的一些发现
问题起源
写编译器课的作业到最后instruction selection的部分,在对比使用Compiler explorer的生成的x86_64汇编代码发现一个很神奇的地方就是对寄存器清零(使用立即数0)的方法。
在创建分支与进行逻辑操作时使用常数0进行比较,我的第一反应是直接使用MOV $0, REG的方法(REG指某一寄存器,下同。),但是发现Compiler explorer会有XOR REG, REG的方法,于是小调研了一下两者的区别。
首先来看一下英特尔的Software Optimization Manual的3.5.1 Instruction Selection 中第7节Clearing Registers and Dependency Breaking Idioms
Code sequences that modifies partial register can experience some delay in its dependency chain, but can be avoided by using dependency breaking idioms.
在Intel Core micro-architecture中可用下列命令将寄存器置零(亦称dependency breaking idioms或zero idioms)
1 | |
然后特别提到
The XOR and SUB instructions can be used to clear execution dependencies on the zero evaluation of the destination register.
之后引出Assembly/Compiler Coding Rule 32
Use dependency-breaking-idiom instructions to set a register to 0, or to break a false dependence chain resulting from re-use of registers. In contexts where the condition codes must be preserved, move 0 into the register instead. This requires more code space than using XOR and SUB, but avoids setting the condition codes.
一开始这些都没明白,但确定了直接使用mov指令和使用其他的指令的两个区别:
MOV指令不会改变ALU的标志位,而XOR和SUB涉及算术运算会更新flagMOV指令长度相较XOR和SUB指令更长。对于立即数$0至少要额外空间来存下这个数
之后继续查询相关资料。
寄存器依赖
在指令流水线中指令会被分为若干阶段执行,指令可能会不按顺序执行。当同时执行的指令发生冲突会产生危险(hazard)。
其中有data hazards, structural hazards和control hazards。依赖就是指data之前的依赖关系,当依赖发生问题时就会出现hazard。 这里我们只看data hazards。
Data hazards
有三种。
read after write (RAW): true dependency
write after read (WAR): anti-dependency
write after write (WAW): output dependency
Read after write (RAW)
1 | |
i2如果在i1前执行会对载入的数据有问题,因为R2可能未及时更新。是真正的依赖。
Write after read (WAR)
1 | |
i2如果在i1前执行会对R5造成影响。解决方法使用寄存器重新命名,如将i2中的R5改为其他寄存器。最有名的是Tomasulo算法。这一过程发生在硬件级别。
Write after write (WAW)
1 | |
同样可通过寄存器重新命名解决。
partial register与假依赖
依赖中只有RAW是真依赖,WAR和WAW都是假依赖。
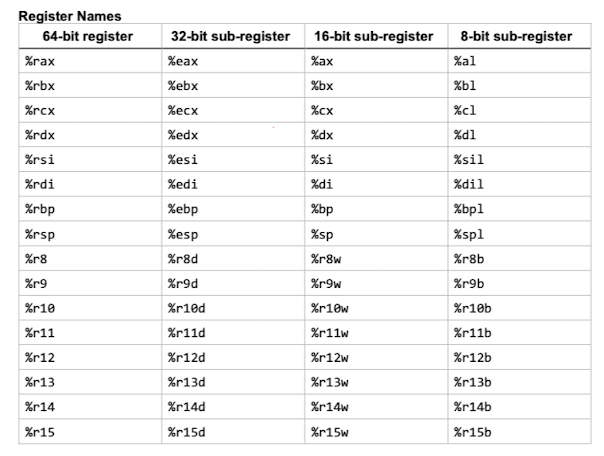
在x86_64中寄存器可有8位、16位、32位与64位进行访问,详见下表。对于32位寄存器来说,小于等于16位的寄存器被称为partial register。 因为都是一个逻辑寄存器,只是访问大小不同,在操作时可能就会因为这一点出现假依赖的问题。
1 | |
代码的原本目的是执行两项完全不相关的工作,但是第四条指令mov ax, [mem3]只改变了寄存器的低16位,高16位仍是前面保留下来的结果。 对于Intel, AMD等公司的CPU来说,它们不会对partial register进行重新命名,也就是第四条指令与前面用的是一个物理寄存器,这使得 mov ax, [mem3]依赖于指令imul eax, 6。
另外有些CPU会对partial register进行重新命名,可以使mov ax, [mem3]不依赖于imul eax, 6,但最后还是要把imul eax, 6 中eax的高16位与mov ax, [mem3]中的ax进行组合,浪费时间。
Zero idioms (dependency breaking idioms)
在Software Optimization Manual的2.1.3 The Out-of-Order Engine中的Renamer(寄存器重新命名器)也提到了
Instruction parallelism can be improved by using common instructions to clear register contents to zero. The renamer can detect them on the zero evaluation of the destination register. Use one of these dependency breaking idioms to clear a register when possible. Since zero idioms are detected and removed by the renamer, they have no execution latency.
回看第一节中的说法就全明白了。
对于使用partial register导致的假依赖如果使用zero idioms,CPU中的renamer会自动handle这一情况,对寄存器清零的同时使上下文不再依赖,同时更新ALU的flag,降低运行延时。
如果在mov ax, [mem3]命令前加上xor eax, eax,会消除因为部分更新导致的依赖。
验证
对于依赖的情况不是很好验证,因为是发生在硬件层面。但对于指令长度而言就好验证多了。
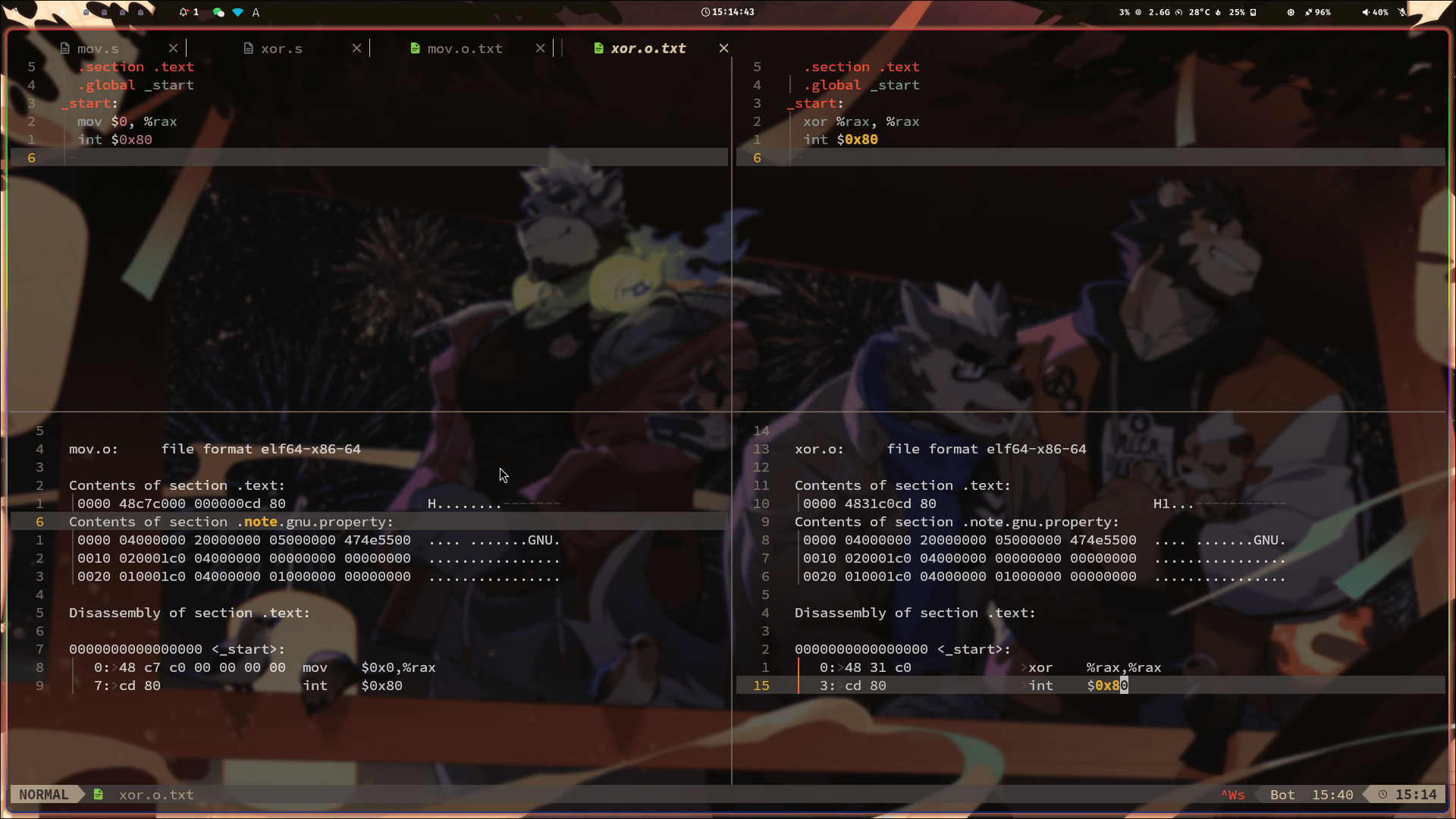
首先尝试在作业的instruction selection上加了特例将const 0的情况使用xor进行处理。然后执行gcc -o a --target=x86_64-apple-macos test.s 看生成的二进制文件大小发现并没有区别。想到我用的是M1芯片的Mac,二进制已经是转成Mac的ARM架构了,而ARM架构指令是定长的与x86_64不太一样不在本文讨论范围,于是转到Arch Linux上 进行实验。
发现使用两个不同的版本生成的二进制文件大小确实不同,使用xor的文件会更小一些。再用最简单方法进一步验证。
首先编写了最简单的两段汇编代码。然后使用as mov.s -o mov.o生成.o文件。再使用objdump查看反汇编内容,命令:objdump -s -d mov.o > mov.o.text.
最终能发现使用mov的机器码确实会比使用xor的要长。单从指令上看mov就要多占用4字节对立即数0(32位)进行存储。
总结
在第一节中介绍的书中的assembly rule会希望大家尽可能使用zero idioms来将寄存器清零。但如果要保持condition的flag则 可以使用mov。最大的影响就是mov指令要引入常数0与12345678这种大数没有区别,指令长度会更长,造成资源浪费。
另,mov和movq后加立即数读取的是一个32位数字,然后将其扩展到64位(对于操作的寄存器是64位而言)。而movabsq是直接读入一个64位数字。
(在学不下习的时候什么都比作业好玩)
References
[1] - https://stackoverflow.com/questions/58090417/why-does-it-take-less-bytes-to-use-xor-than-to-use-mov
[2] - https://blog.eastonman.com/blog/2021/05/modern-processor/
[3] - https://www.intel.com/content/dam/doc/manual/64-ia-32-architectures-optimization-manual.pdf
[4] - https://en.wikipedia.org/wiki/Hazard_(computer_architecture)#Data_hazards
[5] - https://stackoverflow.com/questions/70648350/what-is-false-dependency-in-cpu